[스타트업 IP 가이드] #25. 특허 마이닝(Patent Mining) - AI 분야 전략 및 사례 -
안녕하세요. 길세영 변리사입니다.
특허 마이닝 시리즈의 마지막 연구자료에서는 인공지능(AI) 분야 특허 마이닝 전략과 사례를 소개해 드리고자 합니다.
Ι 인공지능 분야 특허 마이닝 전략
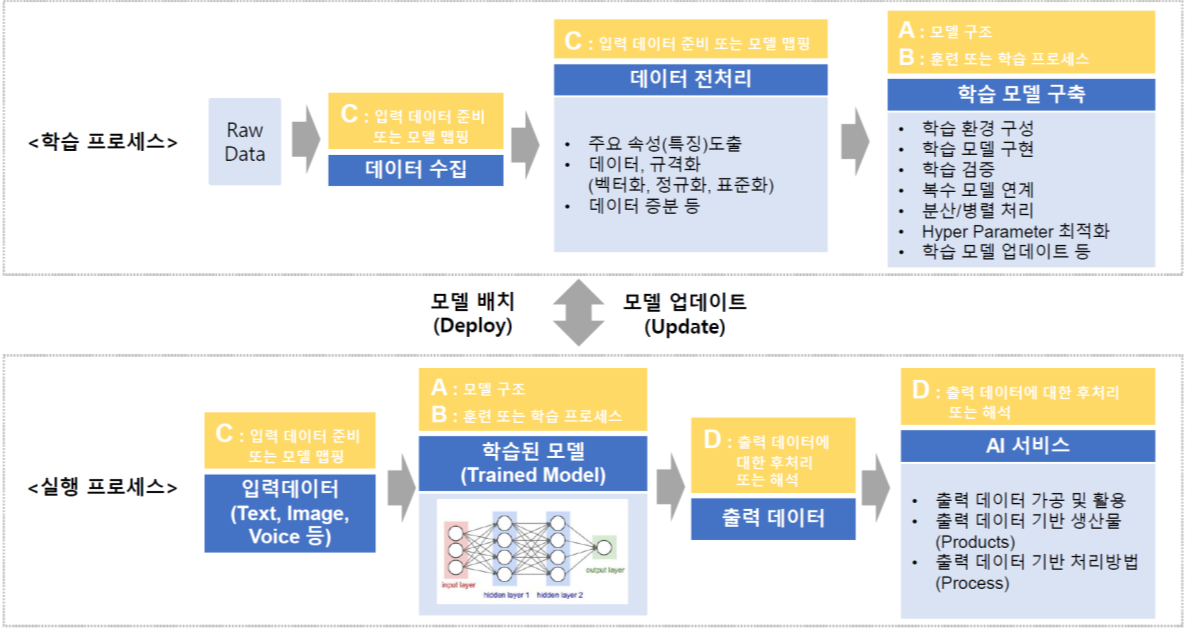
머신러닝 기반 인공지능이 적용된 제품이나 서비스는 학습 프로세스와 실행(추론) 프로세스에 의해 구현됩니다. 그리고, 학습 프로세스와 실행 프로세스를 구성하는 세부 기술요소는 그 각각이 특허 포인트가 될 수 있습니다.
구체적으로, 학습 프로세스 중 데이터 수집, 데이터 전처리(주요 속성 도출, 데이터 규격화, 데이터 증강 등), 학습 모델 구축(모델 구현 및 검증, 모델 연계, 분산/병렬 처리, 파라미터 최적화 등) 등에서 특허 포인트를 발굴할 수 있습니다. 또한, 실행 프로세스에서는 입력 데이터 처리, 학습 모델 배치 및 업데이트, 출력 데이터 가공 등의 과정에서 특허 포인트를 발굴할 수도 있습니다.
많은 분들이 모델 구조(A)나 학습 알고리즘(B)에서 특허 포인트를 찾으려는 경향이 있지만, 실제 연구개발 현장에서는 입력 데이터 처리(C)나 출력 데이터 가공(D)에서 많은 특허가 출원됩니다. 공지의 모델(트랜스포머, GPT, Gemini, DeepSeek 등)이나 학습 알고리즘(강화학습, 지도학습 등) 그 자체에서 완전히 새로운 아이디어를 도출하는 것은 쉽지 않습니다. 오히려, 이를 자사의 제품이나 서비스에 실제로 적용(응용)하는 과정에서 독특한 아이디어가 나오는 경우가 많습니다. 따라서, 자사 제품/서비스를 실제로 구현하는 과정에서 나오는 작은 아이디어들을 모아서 특허 포인트로 정리하면 자사의 제품과 서비스를 보호하고 타사의 모방을 차단할 수 있는 강한 특허를 확보할 수 있습니다.
Ι 의료 인공지능 분야 사례(D사)
D사는 의료 AI를 개발하는 딥테크 기업으로서, 시장을 선점하고 신사업을 보호할 수 있는 특허 포트폴리오를 구축이 필요한 상황에 있었습니다.
D사는 세부 분야(질병)는 다르지만 의료 AI 분야에서 선도적인 역할을 하고 있는 기업의 특허 포트폴리오를 분석했고, 앞서 설명한 인공지능 권리화 기준에 따라 이들 선도 기업의 특허를 분석했습니다. 그 결과, 의료 AI 기업들이 모델 구조나 학습 알고리즘 기술보다 입력 데이터 처리나 출력 데이터 가공 기술에서 더 많은 특허를 보유하고 있는 경향을 확인할 수 있었습니다.
이에 따라, D사는 공지의 AI 모델(LLM 등)을 자사의 제품과 서비스에 적용(최적화, 맞춤화 등)하는 과정에서 개발된 특징에 초점을 맞춰서 다수의 특허 포인트를 발굴할 수 있었습니다. 이렇게 발굴된 특허 포인트는 선행기술과 차별되는 진보성을 갖추고 있었으며, 그 결과 다수의 특허권을 획득할 수 있었습니다.
Ι 맺음말
특허를 발굴하고 특허 포트폴리오를 구축하는 일에는 많은 시간과 노력이 요구됩니다. 긴 시간 동안 노력했지만 만족할 만한 결과물(특허권)을 얻지 못하는 경우도 종종 발생합니다. 또한, 다양한 방법론과 기법 중 어떤 것이 자사에 적합한 것인지 파악하는 것도 쉽지 않습니다.
언제 어디서든 특허를 발굴할 수 있다는 적극적인 자세를 갖추는 것과 함께, 특허 마이닝 및 권리화 전략에 대한 전문가의 조언을 적극적으로 활용하는 것이 중요합니다. 전문가의 도움을 받아 체계적인 특허 전략을 수립한다면, 자사의 기술 경쟁력을 강화하고 효과적으로 보호할 수 있을 것입니다.
본 자료에 게재된 내용 및 의견은 일반적인 정보제공만을 목적으로 발행된 것이며, 특허법인 세움의 공식적인 견해나 어떤 구체적 사안에 대한 의견을 드리는 것이 아님을 알려 드립니다. Copyright ©2025 SEUM IP
